Let's say you are building an application. Your application is built beautifully and solves a real problem.
And now you get real users. It's a surreal feeling, thousands of people are using your application. Now to make sure that the database is up to speed with the increasing demands you scale the database server vertically.
Basically use throw a beefier machine (more CPU, RAM and Storage) at the problem, and you can now safely handle about 3,000 TPS (writes per second) and 10,000 QPS (reads per second).
Now say a someone popular loves your product and tweets about it. The product has gone viral! 🎉
With all the joy it now brings in next step in scaling your application. Let's say now you are getting 50,000+ QPS. And the vertically scaled database is barely managing it.
You see something interesting, with all the increase in traffic most of it are read requests. The read to write ratio of the application is 100:1.
So the application is a read-heavy system.
For read heavy systems a common database scaling technique after using vertical scaling is using read replicas.
Read Replica's
The way it works is that, you move all the reads to other database(s) so that the master database is free to do the writes.
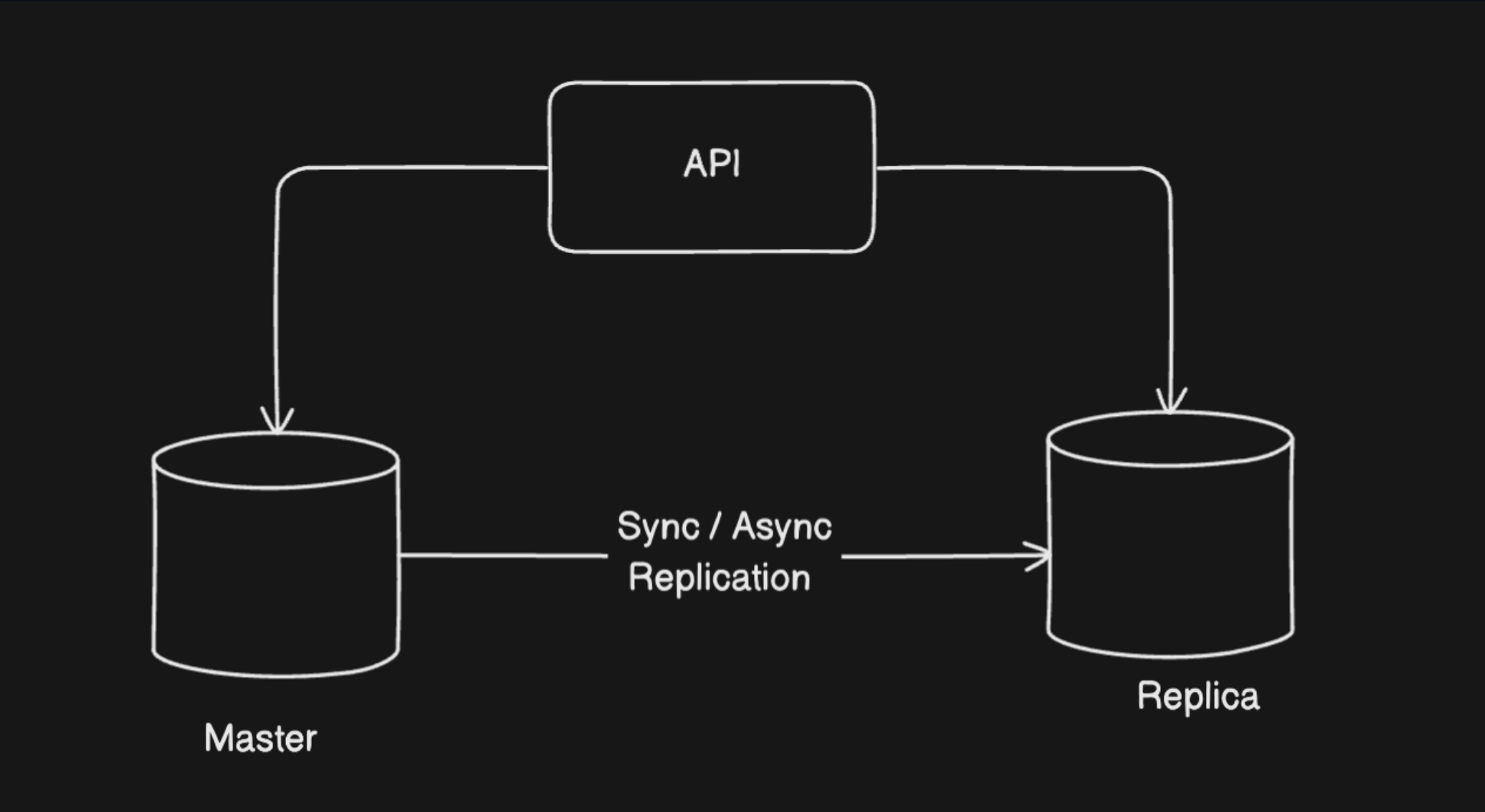
The master database is the source of truth here, any time there is some change in the data it goes to the master database.
To keep all the database in sync we update the replica with the changes made in the master database.
PostgreSQL offers robust replication features that we'll leverage in our Docker-based setup.
Before we start with the implementation, let's understand WAL (Write Ahead Logging)
WAL
Write-Ahead Logging is a standard method for ensuring data integrity where changes to data files must be written only after those changes have been logged.
In simple terms, any modification to your database must first be recorded in a log file before the actual data pages are updated.
It is the foundation that makes PostgreSQL replication possible.
How WAL works
The WAL process follows this sequence:
-
Log First: When you execute a transaction (INSERT, UPDATE, DELETE), the change is first written to the WAL file.
-
Apply Later: The actual data pages are modified only after the WAL entry is safely persisted to disk.
-
Crash Recovery: If the system crashes, PostgreSQL can replay the WAL entries to restore consistency.
This approach provides several benefits :
- Reduced Disk Writes: Only the WAL file needs to be flushed during transaction commit
- Sequential Writing: WAL files are written sequentially, making them much faster than random data page writes
- Point-in-Time Recovery: WAL enables backup and recovery to any specific moment
- Replication Foundation: WAL records are streamed to replica servers for synchronization
WAL Components
PostgreSQL's WAL system consists of several key components :
WAL Files: Binary files storing transaction records, typically 16MB each, located in the pg_wal directory
WAL Buffers: Memory areas that temporarily hold WAL data before writing to disk
Checkpoints: Points where all dirty pages are guaranteed to be written to disk, enabling faster recovery
Log Sequence Numbers (LSN): Unique 64-bit identifiers that track positions within the WAL stream
Great! Now we can start with the implementation.
Implementation
Let's examine our PostgreSQL replication setup and understand each configuration parameter:
- Create a
docker-compose.ymlfile
- Launch the containers
-
Check that both containers are running:
-
Connecting to the master and creating test data:
-
Connect to master
-
Create test table and insert data
-
-
Verify data replication on the replica
-
Connect to replica
-
Check replicated data
Great! If you see the same data on the replica server that was inserted into the master database, you have successfully created database replication setup using PostgreSQL and docker.
Deep dive
Now let's understand how things are working? How did the replication actually happened? And what other options do we have to configure this behaviour?
How does this work?
Remember this line from the compose file?
It sets the following properties under the hood
wal_level = replica- Enables WAL logging sufficient for streaming replicationmax_wal_senders = 8- Allows up to 8 concurrent replica connectionswal_log_hints = on- Required forpg_rewindfunctionality
Basically this configures the system for streaming replication (aka WAL replication)
It works as follows:
-
Write-Ahead Logging (WAL): When data is modified on the master, PostgreSQL first writes the changes to WAL files before applying them to the actual data files. This ensures durability and crash recovery.
-
WAL Streaming: The replica connects to the master using the replication user credentials and continuously receives WAL records as they're generated. This happens in near real-time.
-
Replay on Replica: The replica receives these WAL segments and replays them, applying the exact same changes that occurred on the master. This keeps the replica synchronized.
Key Characteristics
Asynchronous by default: In our current setup, the master doesn't wait for the replica to confirm if it has received the data before committing transactions. This provides better performance but means there's a small window where committed data on the master might not yet be on the replica if the master crashes.
Physical replication: The replica is a byte-for-byte copy of the master. It replicates at the storage level, not the logical SQL level. This means:
- The entire database cluster is replicated (all databases)
- The replica is read-only
- Both servers must be the same PostgreSQL version
Continuous: The connection stays open, and changes flow continuously rather than in batches.
Here are some Pros and Cons of this approach:
Pros:
- Better performance: The master doesn't wait for replica confirmation, so write operations are faster
- No blocking: If the replica goes down or network has issues, the master continues operating normally
- Lower latency: Transactions commit immediately on the master
- More resilient: Master availability isn't dependent on replica health
Cons:
- Potential data loss: If the master crashes before the replica receives recent changes, those transactions are lost
- Replication lag: The replica might be seconds or minutes behind during high load
- No guaranteed consistency: Reads from replica might show stale data
The Bitnami image we've handles the complexity automatically:
- The master is configured with
POSTGRESQL_REPLICATION_MODE=master - The replica connects using the replication user and automatically starts streaming
- The replica stays in "hot standby" mode (read-only but queryable)
Now let's try to change our setup to Synchronous Replication
Configuring Synchronous Replication
To make your replication synchronous, you need to modify both the master and replica configurations:
Most of the setting are same, here are the updates again:
POSTGRESQL_SYNCHRONOUS_COMMIT_MODE=onon the masterPOSTGRESQL_NUM_SYNCHRONOUS_REPLICAS=1on the master (specifies how many replicas must confirm)POSTGRESQL_CLUSTER_APP_NAME=postgres-replicaon the replica (gives it an identifier)
How does this work?
PostgreSQL's synchronous replication builds on the same WAL streaming foundation but adds confirmation steps:
-
Write-Ahead Logging (WAL): When data is modified on the master, PostgreSQL writes the changes to WAL files first, just like in asynchronous replication.
-
WAL Streaming with Acknowledgment: The master streams WAL records to the replica(s), but now it waits for a response. The replica receives the WAL data and sends back an acknowledgment to the master confirming receipt.
-
Transaction Commit Blocking: The master transaction waits at the commit phase until it receives acknowledgment from the required number of synchronous replicas (defined by
synchronous_standby_names). Only after receiving confirmation does the master complete the commit and return success to the client. -
Replay on Replica: After acknowledging receipt, the replica applies the WAL changes to its data files. The acknowledgment can happen at different stages depending on the
synchronous_commitlevel:remote_write: Replica confirms after receiving WAL (in memory)on: Replica confirms after flushing WAL to diskremote_apply: Replica confirms after actually applying changes to database
Key Characteristics
Blocking commits: The master waits for replica acknowledgment before completing transactions. This creates a synchronous barrier where the client application doesn't receive a "commit successful" response until the replica confirms it has the data. This guarantees durability but increases transaction latency.
Zero data loss guarantee: Because transactions only commit after replica confirmation, there's no window of vulnerability. If the master crashes immediately after a commit, the committed data is guaranteed to exist on at least one replica.
Physical replication: Like asynchronous mode, this is still physical replication at the storage level:
- Entire database cluster is replicated
- Replica remains read-only (hot standby)
- Both servers must run the same PostgreSQL version
- Byte-for-byte identical copy
Quorum-based: You can configure how many replicas must acknowledge (POSTGRESQL_NUM_SYNCHRONOUS_REPLICAS=1 means at least 1 replica). With multiple replicas, you can specify that any N replicas must confirm, providing flexibility and redundancy.
Degraded mode behavior: If all synchronous replicas fail, the master has two options:
- Block all writes until a replica comes back (safest, but affects availability)
- Fall back to asynchronous mode (requires manual configuration change)
Network dependency: The master's write performance is now directly tied to network latency to the replica. A slow network or distant replica will slow down all write transactions proportionally.
Pros and Cons for this approach
Pros:
- Zero data loss: Transactions only commit after at least one replica confirms receipt
- Guaranteed consistency: The replica is always up-to-date (within the synchronous set)
- Better for compliance: Meets strict data durability requirements
- Reliable failover: You can promote the replica knowing it has all committed data
Cons:
- Performance impact: Every write waits for network round-trip to replica, increasing latency (can be 2-10x slower)
- Availability risk: If the replica fails or network partitions occur, the master can block writes (or you need to disable sync replication)
- Single point of failure: The replica's health directly affects master's ability to accept writes
- Higher operational complexity: Need monitoring and failover procedures
Summary
In this guide, we've tackled a crucial step in scaling a growing application: handling high read traffic. We started by understanding the limitations of vertical scaling and introduced read replicas as a powerful solution for read-heavy systems.
We dove into the foundational technology of PostgreSQL replication, the Write-Ahead Log (WAL), which ensures data integrity and makes streaming replication possible.
Using Docker Compose, we built a practical master-replica architecture, demonstrating the two primary modes:
- Asynchronous Replication: The default, high-performance setup where the master doesn't wait for the replica, prioritizing speed over guaranteed data consistency.
- Synchronous Replication: A more robust configuration that ensures zero data loss by requiring the master to wait for confirmation from the replica before committing a transaction, trading latency for durability.
By walking through both implementations and their respective pros and cons, you're now equipped to choose the right strategy based on your application's specific needs for performance and data safety.
Choosing Your Replication Strategy
To make the decision clearer, here's a quick guide for when to use each approach:
Use Asynchronous When...
- Performance is critical and you need the fastest possible write speeds.
- You can tolerate losing a few seconds of data in a worst-case disaster scenario.
- You want maximum availability for the master database, even if replicas are disconnected.
- You have multiple replicas for redundancy and distributing read load.
Use Synchronous When...
- Zero data loss is unacceptable, such as for financial transactions or critical user data.
- Compliance regulations require guaranteed data durability across multiple nodes.
- You can accept the performance trade-off of higher write latency for increased data safety.
- You have a highly reliable and low-latency network between your master and replica.
A Hybrid Approach
You can also find a middle ground. By configuring synchronous_commit = remote_write instead of on, the master waits for the replica to confirm it has received the data in memory, but not that it has been flushed to disk. This provides a better balance between performance and durability than the strictest synchronous mode.
Closing Thoughts & Where to Go From Here
Congratulations! You've successfully set up a fundamental database replication architecture. This is a massive step towards building a resilient and scalable application.
However, we've only just scratched the surface here. A production-ready system requires more than just a master and a replica. Here are some key concepts to explore next on your journey to mastering database architecture:
-
Automatic Failover and High Availability (HA): What happens if your master server crashes? Manually promoting a replica works, but for true high availability, you need an automated process. Look into tools like Patroni, repmgr, or Stolon that can manage failover for you, ensuring your database remains online with minimal downtime.
-
Read/Write Splitting & Load Balancing: Your application now has two databases, but how does it know where to send read queries versus write queries? This is typically handled by a connection pooler or a load balancer. Tools like PgBouncer (for connection pooling) and Pgpool-II (for load balancing and query routing) are essential for directing traffic efficiently.
-
Monitoring Replication Lag: In an asynchronous setup, it's critical to monitor how far the replica is lagging behind the master. You can query the
pg_stat_replicationview, but for production, you'll want to integrate this with a monitoring system like Prometheus and Grafana to get alerts when the lag exceeds an acceptable threshold. -
Backup and Disaster Recovery: Remember, replication is not a backup. If you accidentally delete data on the master, that deletion will be faithfully replicated to the slave. You still need a robust backup strategy using tools like
pg_dumpand continuous archiving withpg_basebackup. -
Logical Replication: We used physical replication, which copies the entire database cluster byte-for-byte. PostgreSQL also offers logical replication, which allows you to replicate changes on a more granular level, such as replicating only specific tables or even filtering rows.
This foundation is solid. Now you can build upon it to create truly resilient, highly available, and scalable database systems. Happy scaling! 👋